


Terramate for streamlined AWS infrastructure management
STEP by STEP guide


Overview
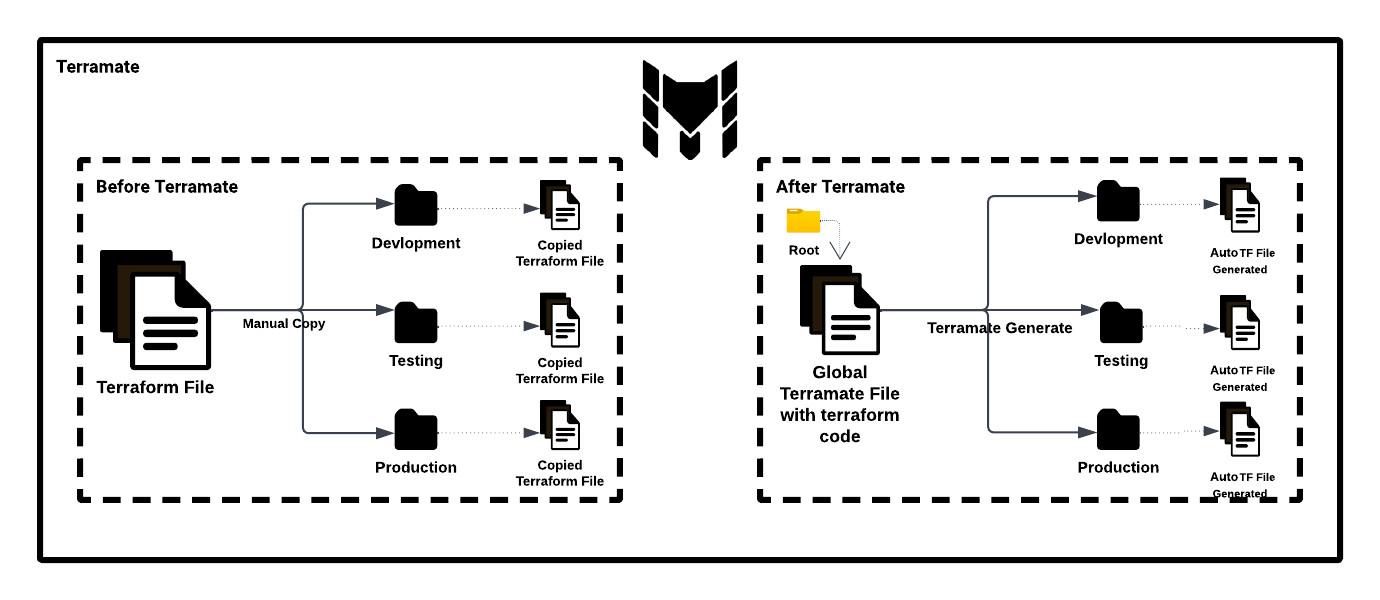
In this blog post, we are thrilled to unveil an exceptional capability of Terramate that addresses the challenge of code redundancy with the DRY (Don't Repeat Yourself) principle. Through this demonstration, we will exhibit how Terramate empowers us to build AWS infrastructure more efficiently and concisely.
We'll showcase one of Terramate's key features – sharing data with globals. We'll delve into the concept of globals and how it can be employed to streamline similar types of code across different contexts. These globals can also be put in terramate.tm.hcl file, which is used in non-git environments to use Terramate. At the runtime Terramate combines all the .tm.hcl as one file, so you can put your globals anywhere in the stacks while remembering the hierarchy of the stacks. A stack can generate all the globals in the stacks that reside in itself, and can not work out of the stack.
Our focus will be on creating AWS infrastructure using Terramate across three vital environments in actual infrastructure: Development, Staging, and Production to name them. Through a comparative approach, we'll demonstrate the efficiency of Terramate in configuring the same S3 bucket settings for all three environments, highlighting its practical application in real-world scenarios.
Agenda
Creating S3 Bucket for multiple environments.
Understanding the DRY concept.
Understanding the usage of Terramate globals.
Auto-generating all Terraform config files using Terramate.
What are we doing here?
We will be spinning up Infrastructure for AWS S3 buckets for multiple environments.
Subsequently, we will learn how to keep your code DRY(Don’t Repeat Yourself), with Terramate.
By the end of this blog, you will learn:
Creating AWS infrastructure (S3 bucket in this blog) with Terraform and Terramate.
How to share data by using the Terramate globals.
Avoid copying and pasting of the same code.
Use the best practices to keep your code DRY.
Let’s get Started…
Terraform code we will be using to create the S3 Bucket.
Let’s consider a scenario, where your boss asks you to create one S3 bucket for each environment, such as Development, Staging, and Production.
There are two ways to do that,
Manual copying and pasting, just like a robot we spend a lot of time copying and pasting all the code again and again.
Using a better and smarter approach with Terramate, a tool that can reduce your copy-pasting of code and help in keeping your code more readable and easy to make changes in your code as well.
Let’s start with writing all the files required in both the cases
resource "aws_s3_bucket" "infraSity" {
acl = "private"
versioning {
enabled = true
}
}
The above code is creating an S3 Bucket in your AWS account, we will be using it for creating buckets for all 3 environments (Development, Production, and Testing).
The name is optional, you can give any name as you like.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
}
}
}
provider "aws" {
region = "ap-northeast-1"
access_key = "<your_key>"
secret_key = "<your_secrets>"
}
Manual Copying
We will be using VS Code as a code editor in this blog, you are free to choose your favorite IDE.
Create 3 folders.
Make two files, 1st for the provider.tf where AWS provider configuration code is written, 2nd for main.tf where all S3 bucket creation code is written.
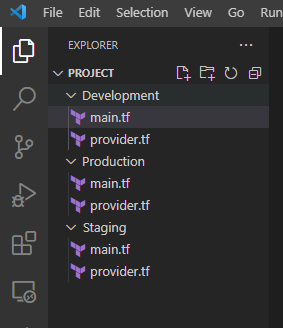
Now paste all the Code into each folder since this is a Terraform vanilla approach.
Code in provider.tf of each folder.
Code in main.tf in each folder.
NOTE: We know the above step is tedious, in the next section with Terramate we will learn where we won't have to copy the same code multiple times, we will use Terramate globals and write once to generate multiple code approach, keeping our code DRY which was tedious to achieve in vanilla Terraform
Now run “terraform init”, and “terraform apply” in each environment /folder to spin up the infrastructure.
To do that, you are required to change the directory (cd) to each folder and run the terraform commands.
After applying all the code you have 3 S3 buckets built, one for each environment.
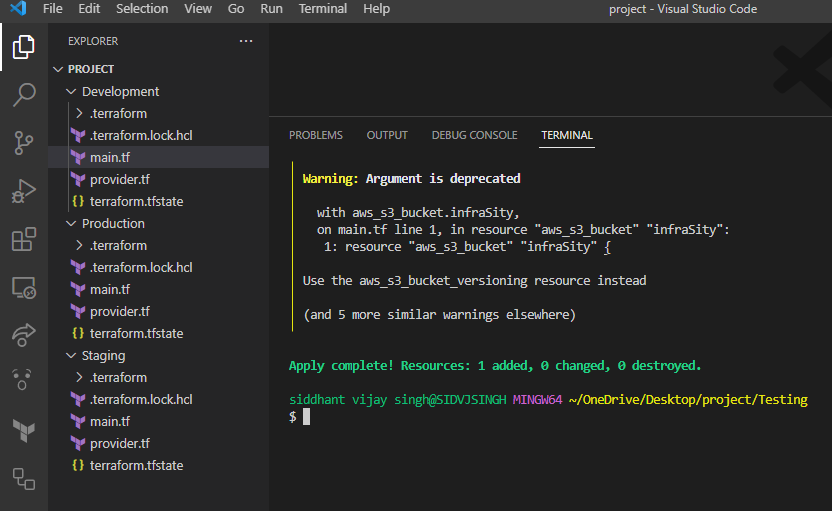
Check your AWS account.
Search for S3 in the search bar.
And click on it, you will see 3 buckets provisioned in your account.

Note: Since the name is optional for the bucket, terraform chooses a name by itself if you don’t mention it in the resource block.
The problem with the above approach
Excessive copying and pasting of identical code in multiple environments such as Development, Staging, and Production as mentioned above.
Increases the risk of human errors while copying paste, for example, maybe you missed adding the right tag in the block that is required while writing the block.
Consumes significant time, especially when working on a larger scale, Imagine working on a multi-infra deployment of multiple EC2, Lambda, and S3 in that case copying and pasting the same code would be tedious.
Contradicts best practices(DRY) for maintaining clean and organized code.
Terramate (A different approach)
We will try to replicate the same infrastructure creating S3 buckets for three different but this time with Terramate and figure out the world of difference.
With Terramate you need a single root directory and inside that root directory 3 more folders, in Terramate terminology, we call them Stacks.
Stacks are the directory (for example Production, Development, and Staging in our case) that contains all the Terraform files.
To create stacks using Terramate you will be required the below code in your root directory if you are doing all your work in a non-git environment.
/* File name: terramate.tm.hcl */
terramate{
config{
}
}
In your root directory, Create a root stack by using the “terramate create <stack_name>” command in your terminal of the code editor. We're using VS code here.

Rename it’s “stack.tm.hcl*” file to “main.tm.hcl**”, since it contains our globals.*

Now inside that stack creates 3 more stacks with names as:
DevelopmentStagingProduction>> representing each environment phase.
Since this is a non-git environment, we will be required to add a terramate.tm.hcl file in the root stack as well, which is “S3” in this case.

Now to generate “main.tf” and “provider.tf” in each phase you just need to define it in the root’s “main.tm.hcl” file.
What is the “stack.tm.hcl” file?
Each time we create a stack using the “terramate create <stack_name>” command it creates a folder and a file for us, that file is “stack.tm.hcl” and this specific file contains a unique id of that stack, you can define your Terramate code to generate in this or any other .tm.hcl file in this directory only, to create your Terraform code for the directory.
Sample content of “stack.tm.hcl” file:
stack {
name = "S3"
description = "S3"
id = "c03ba8a4-acd6-44eb-843e-680f82e2bc5e"
}
Code for “main.tm.hcl”(present in the root) file to generate main.tf and provider.tf for each environment(folder):
stack {
name = "S3"
description = "S3"
id = "c03ba8a4-acd6-44eb-843e-680f82e2bc5e"
}
globals {
aws_provider_version = "4.27.0"
aws_region = "ap-northeast-1"
aws_access_key = "<your_access>"
aws_secret_key = "<your_secret>"
}
generate_hcl "provider.tf" {
content {
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = global.aws_provider_version
}
}
}
provider "aws" {
region = global.aws_region
access_key = global.aws_access_key
secret_key = global.aws_secret_key
}
}
}
generate_hcl "main.tf" {
content {
resource "aws_s3_bucket" "infraSity" {
acl = "private"
versioning {
enabled = true
}
}
}
}
File structure for Terramate
terramate.tm.hcl (in the root, for the non-git environment, for content see above)
main.tm.hcl - Present in the root of the folder, this is the global file that tracks what to generate in which folder [Very Important step]
Insider every stack or folder - stack.tm.hcl (auto-generated, no changes made on this)
The Global file (main.tm.hcl mentioned in step 2 above) code contains 3 main blocks:
globals:
That contains all global elements which can be used in preceding blocks later.
Here we have declared
Aws provider version
Aws region
Aws access key
Aws secret access key
generate_hcl for “provider.tf” file:
- That contains all “provider.tf” code with all specific versions declared above in the global block.
Now that’s all you have to do to structure your environment’s stacks.
All other things will be taken care of by the directory where your global stack file is present command and see the magic of Terramate.
Before the command:

After the command “terramate generate” you will see below changes in your directory: Terramate :), you just need to go to your terminal of the code editor and write “terramate generate” on your root

For each stack, all “main.tf” and “provider.tf” files were generated successfully.
Now cd to each folder and apply the Terraform to see the buckets in your AWS account, running Terraform individually in each folder is beneficial only when you want to apply in one environment and not in another.
However, if you wanted to terraform apply in all the folders(environments) together without cd’ing into each folder, with terramate run terraform Apply you could apply all the infra for all the stack at once, see the below screenshot.

In the same manner, you can use terramate run terraform destroy to destroy all the applied changes to the infrastructure.
NOTE: terramate run followed by any terraform command will work to run on all the stack at once and make your Infrastructure.
Below is what your Root Folder looks like after all the terraform init and terraform apply commands in each environment (Development, Production, Staging).
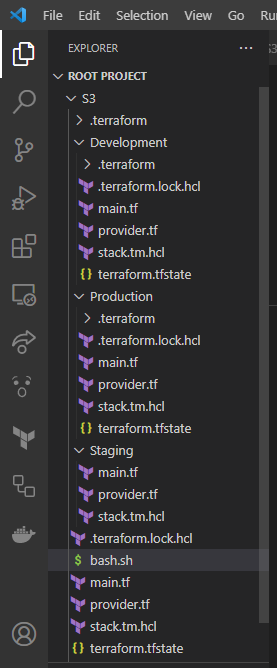
Now you can check your AWS account for S3 buckets:
Go to your AWS account.
Search for S3 in the search bar.
You will find 3 buckets generated there just as below.

There you have your S3 buckets created for your environments using Terramate.
Looking for the complete code that is demonstrated above, here it is.
To sum this up:
We created Infrastructure (S3 bucket for 3 different environments) in 2 ways,
Manual Copy paste
By using Terramate
- We were able to write out Terraform code once in a global file in the root and were able to generate it for multiple environments in our case
Terramate has simplified our Terraform experience, and we believe it can do the same for you. So why wait? Give Terramate a try and improve your Terraform experience today!